백준 그룹단어 체커


코드 리뷰)
맨 윗 줄에는 단어의 개수 n을 입력받고, 단어 n개를 입력받기 위해 반복문을 사용하였다.
단어를 입력 받으면, 일단 결과를 0으로 초기화하고 문자열 a의 요소를 하나하나씩 탐색한다.
만약 문자열에 들어있는 문자의 갯수가 1개가 넘는다면, 반드시 연속으로 있어야 그룹단어가 되므로 조건문을 사용하여 해당 문자가 나타나는 맨 처음 인덱스와 맨 마지막 인덱스를 구한다. 그래야 처음 인덱스~ 마지막 인덱스까지 해당 문자만 있는지 확인할 수 있기 때문이다.
여기서 마지막 인덱스를 구하기 위해서 a.rfind(찾고자하는 문자)를 사용하였다.
그 다음, 처음 인덱스 ~ 마지막 인덱스까지 반복문을 사용하여 훑어봤는데, 만약 그 사이에 문자열에 해당 문자가 아닌 문자가 온다면, result=1로 두어 그룹단어임을 나타내도록 하였다.
그 후, 중복된 문자를 제거해주어야 다시 반복문이 안돌아가므로 (만약에 어떤 문자가 문자열에 3개가 있다면, 그 문자가 나올 때마다 반복문 조건을 충족하므로 계속 검사를 해줘야하는데 여기서 오류가 발생하므로 지워줘야 한다.)
반복된 문자를 *로 바꿔주었다
→ 삭제도 해봤는데 단어 길이가 짧아져서 다음 단어가 반복문에 들어갈 때 범위 오류가 발생한다.
마지막으로, 만약 길이가 1인 단어 1개를 입력받는다고하면,
위의 그룹단어 판정에서 그룹단어가 아닌게 판명되고, 아래에서 또 조건을 만족하여 그룹단어 갯수가 더해지게 되므로
단어의 개수가 1일 경우와 아닐 경우의 조건문을 작성하여 그룹단어의 숫자를 예외없이 셀 수 있게 작성하였다.
+) 문자가 연속으로 오는 것이 맞는지 확인하는 반복문 로직에서 if문 안에 break를 사용하면 굳이 끝까지 검사하지 않고 한 번이라도 연속을 만족하지 않으면 빠져나오게끔하면 더 좋을 것 같다.
2023.01.03 복습
위의 문제를 복습하다가 더 시간을 단축할 수 있는 풀이로 풀게 되어 추가로 코드 작성을 하고자 한다.
n = int(input())
cnt = 0 # 그룹단어의 갯수
a = [] # 이미 연속 검사를 수행했던 문자들을 모아둘 리스트
for i in range(n):
s = input()
flag = 0 # 그룹단어인지 체크하기 위한 변수
for j in range(len(s)): # 단어의 길이만큼 반복문 수헹
if s[j] not in a: # 만약 리스트에 들어가지 않은 문자일 경우
a.append(s[j]) # 해당 문자를 리스트에 추가
if s[j] in a: # 해당 문자가 이미 리스트에 들어가 있을 경우
if a[-1] != s[j]: # 리스트의 맨 마지막에 들어가 있지 않으면 연속을 만족하지 않음
flag = -1 # 그룹단어 x
break # 반복문을 빠져나옴
a = [] # 새로운 단어를 입력받기 전에 리스트를 초기화
if flag == 0: # 만약 그룹단어일 경우
cnt += 1 # 그룹 단어의 갯수를 1씩 증가
print(cnt)
코드 리뷰)
문자열을 입력받으면 해당 문자열을 하나씩 탐색해보며 처음 방문하는 문자는 이미 방문한 문자인지 아닌지 체크하기 위해 리스트에 넣었고, 이미 방문했던 문자는 연속 조건을 만족해보는지 확인하기 위해 조건문을 걸어 가장 마지막에 방문한 문자와 같은지 확인하는 로직을 작성하였다.
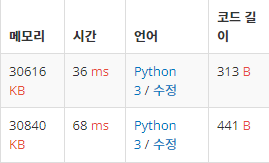
위의 두 코드를 비교해보면, 아래의 코드가 메모리, 시간 소요, 간결성 측면에서 더 좋다고 볼 수 있다.